lalr1是一个用Rust编写,可以生成多种目标语言(目前实现了Rust, C++, Java)的parser generator。
在线演示网站:https://mashplant.online/lalr1。不过其实演示的内容与lalr1的使用没有什么关系,只是用图形或者文字展示一下各种分析表,状态机,大概可以用来算编译原理的作业答案吧。
lalr1的parser生成可以选择基于LALR1(1)文法或者LL(1)文法,鉴于我考虑到应该不会有人在可以使用LALR1(1)文法的情况下用LL(1)文法,这里不会介绍选择LL(1)文法时的用法。其实这个LL(1)文法的版本就不应该存在的,只是以前的decaf实验中有这么一个任务,我才做了这个支持,正常人怎么可能想用LL(1)文法呢。
lalr1生成parser的同时也生成了lexer,lexer内部的自动机是基于同样由我编写的re2dfa实现的。lalr1和re2dfa已经经受住了2019年的编译原理课的检验,不过这一套工具链毕竟不可能像flex,bison那样成熟,所以还是可能有一些不稳定因素,如果遇到了影响使用的bug,希望能够积极汇报。
lalr1有两套代码生成的方式,一种是利用Rust的过程宏,在Rust代码中嵌入产生式的信息,这一种显然只支持生成Rust代码;另一种是读取TOML配置文件并输出代码,这一种支持上面说的三种语言。下面两节分别介绍这两种方式,你只需要阅读你选择的方式对应的一节,之后的两节”解决冲突”和”字符集”是general的,两种方法中都存在相关的概念。
过程宏
过程宏(Procedural Macros)是Rust的一种语法特性。简单来说,过程宏的编写者定义了一个特殊的函数,它在Rust的编译过程中接受Rust的语法树,在执行任意的变换后返回一个新的语法树。这里不必完全了解过程宏的所有形式,只需要了解lalr1这个库中定义的过程宏怎么使用即可。下面这些小节会分别介绍一些使用上需要注意的点,如果觉得理解有困难,可以结合最后一小节”一个完整的例子”一起阅读。
在你希望成为一个parser的struct的impl块上添加#[lalr1(Start)]属性,其中Start是一个非终结符,是parser希望规约出来的最终结果。另外一个必要的属性是#[lex = "TOML of lexer"],以TOML字符串的形式定义了词法分析器。此外还可以为impl块添加一些可选的属性,后面会详细描述。对于impl块中的每个函数,都使用Rust的正常函数的语法来编写语义动作,同时用函数级别的属性来描述产生式。
生成出来的Rust代码中不会保留这个impl块,也就是说这里面编写的东西都不会直接被编译。输出的结果包含两个enum,即TokenKind和StackItem,两个struct,即Token和Lexer,并为你希望成为parser的struct定义一个parse函数。根据我的使用经验,现在的IDE或者编辑器不太可能把这些符号识别出来并且给予正常的语法提示,如果希望了解具体的API的话,可以使用后面会提到的#[expand],也可以使用rust doc,它会在展开过程宏后再分析API。
编写lexer
#[lex = "TOML of lexer"]的TOML字符串中应该包含priority和lexical两个字段,前者用于指定终结符的优先级和结合性,排在后面的优先级高(其实这与lexer没有任何关系,完全是parser的性质,不过在这里定义它比较方便);后者用于指定终结符的正则表达式,排在前面的优先级高。
每次生成token时,lexer从剩余的字符串的开头查找一个最长的匹配。例如在下面的例子中,字符串int1中的int部分匹配Int的正则表达式,但是int1匹配Id的正则表达式,且更长,所以生成一个Id token;字符串int同时匹配Int和Id的正则表达式,但是Int排在前面,优先级更高,所以生成一个Int token。
一个简单的的例子如下:
1 |
这其中Add,Mul这些就是终结符的名字,在定义产生式的时候会用到,产生式中不支持直接用终结符的字符串形式来表示终结符,例如yacc/bison中可以写Expr: Expr '+' Expr,lalr1中是不行的,只能写成Add。
lexer中包含三个预定义的终结符:
_Eps:表示解析出这个结果时,lexer不应该告诉parser找到了一个终结符,而是忽略它继续解析下去。这个例子里遇到多个连续地空白字符时返回_Eps,parser就可以正确地忽略空白字符_Err:表示无法识别的输入,一般情况下lexer在遇到无法识别的输入时会返回一个_Errtoken,而且不会消耗输入字符串,也就是说之后无论调用它多少次都会返回_Errtoken。如果像这个例子一样,主动识别.,也就是遇到任意不符合上面的的模式的字符时返回_Err,那么输入字符串会被消耗(因为匹配了.),下一次调用就会跳过这个字符_Eof:在字符串结束时自动生成一个提供给parser,告诉parser输入结束了
生成出来的Lexer是可以独立于Parser使用的,下面的代码可以依次输出从一个字符串中解析出的全部token:
1 | let mut lexer = Lexer::new("your string here".as_bytes()); |
re2dfa支持一个正则表达式的子集,这里列举几个不符合正则标准的地方
- 不支持
{n},{m,n},^,$,但是{,},^,$仍然需要用\来转义,直接用会报错 ()没有分组作用(当然,因为这里根本没有分组这个概念)- 只支持贪婪匹配
- 虽然支持
\s,\d,\w,但不支持\S,\D,\W .就是识别所有字符,而不是识别所有非换行符的字符[]内不支持多字节字符
其余功能的支持也不一定完整,如果遇到了什么不符合直觉的结果可以把lexer单独拿出来调试一下,如果的确是re2dfa没有支持的话,就暂且换一个更简单的方法来实现吧,毕竟理论上正则只需要拼接,|和*就可以实现所有功能了。
有一些正则表达式虽然合法,也可以构造出正常的自动机,但是这些自动机可能不适合用于lexer。这样的正则表达式有两种,一种是不接受任何字符串,一种是接受空串。之所以说它们不适合用于lexer,是因为在遇到一些corner case的时候比较难以定义它们的行为,例如:
- 如果输入是空字符串,不接受任何字符串的自动机应该返回
_Eof还是_Err? - 在字符串尾的时候,接受空串的自动机应该返回
_Eof还是对应的token?
出于这样的原因,lalr1(而不是re2dfa,因为从自动机的角度来说它们是完全合法的)禁止这样的正则表达式。
impl块的可选属性
除了#[lalr1(Start)]和#[lex = "TOML of lexer"]这两个必要的属性外,还可以添加几个额外的属性,目前支持的有以下几个:
#[verbose = "output path"]向指定路径输出一些用于调试的信息。
调试信息首先包括文法符号的编号及其对应的名字,产生式的编号及其对应的内容,剩余部分依据使用的文法而定。使用LALR(1)文法时为action表,出现冲突警告的时候可以利用这个文件来帮助查找语法中的问题。action表中包含每个节点包含的产生式及点的位置(不包含向前看符号),以及每个节点处遇到终结符时的移进/规约/接受动作。每个动作都会在后面加上一个表示冲突情况的符号,示例如下:
1
2
3
4A => Shift(1) (✓)
A => Reduce(1) (-)
B => Shift(2) (✓)
B => Reduce(2) (✗)其中
(✓)表示它最后被解析器采用,(-)表示它被利用优先级和结合性消除了,(✗)表示它被”强行”消除了,对应于一个冲突警告。详见后面的”解决冲突”一节。#[log_token]在生成的代码中,每当新解析出一个非
_Eps的终结符时,输出它的相关信息,也就是输出一个structToken,包括token类型,字符串片段,行号列号。#[log_reduce]在生成的代码中,每当执行一次规约时,输出产生式。
#[use_unsafe]在生成的代码中使用一些
unsafe来减少运行时检查,以期提高性能。例如将不可达断言转化成不可达hint,取消下标越界检查等。理论上无论你编写的parser是什么样的,无论输入的字符串是是什么,只要成功生成代码并且成功编译了,这些
unsafe都不会导致任何未定义行为(至少lalr1的目标是这个,至于是否真的达到了,目前暂且不能做出保证)。#[expand]输出生成的代码。之所以添加这个选项而不建议大家使用
cargo expand来查看生成的代码,是因为后者把所有宏都展开了,不利于阅读或者调试,而且后者要求编译过程至少成功进行到了某个阶段(具体哪个阶段我还不清楚)才会输出,这对帮助解决编译错误可能是没有帮助的。lalr1生成的Rust代码不包含位置信息,所以parser中的编译错误和运行错误都无法得知具体在什么位置,而如果使用
#[expand]输出的代码来代替整个impl块,效果是完全等同的,这样可以方便调试或者看自己具体那里编译出错了。#[show_fsm = "output path"]和#[show_dfa = "output path"]分别把parser的lr fsm和lexer的dfa的图形以dot文件的形式输出到对应路径中。其实是没啥用的一个功能,对于稍微有一点意义的语法,这两个自动机都太大了,甚至dot文件都不一定能顺利地渲染成图片,更不用说靠人眼从中提取什么有用的信息了。
产生式和语法动作
在impl块内部将产生式和语义动作结合起来,以函数的形式编写代码,一个例子如下:
1 |
|
以下几点需要注意:
- 生命周期
'p是硬编码的,这意味着你把所有的'p都换成'a或者别的什么的,是不能work的。当然,理论上可以在过程宏中更加精细地提取代码中的这些信息,但是我想了一下,感觉收益明显小于付出,不多费事了 - 它虽然看起来是一个函数,但是其实不是,它的函数体会被提取出来当成代码段嵌在一个大函数中,所以不要在里面写return之类可以改变控制流的语句
- lalr1会对参数进行类型检查,保证一个非终结符只能对应于一个类型,保证终结符一定对应
Token类型,但是这个检查完全是基于字符串比较的,并不会考虑任何Rust层面的语义信息(如类型别名),所以是有可能把两个相同的类型判定为不相同的。编写类型也可能带来很多冗余,但是我认为这是有必要的,这是为了最大程度的保证生成器生成出来的代码能够通过rustc编译,避免后续产生不必要的编译错误
函数上还可以添加一个属性:#[prec = "Term"],这是指定这条产生式的优先级与终结符Term相同。具体作用的会在”解决冲突”一节描述。
一个完整的例子
下面以一个解析四则运算表达式的parser为例子讲解:
1 | struct Parser; // 用户希望成为parser的struct |
跑一个实际的例子:
1 | assert_eq!(Parser.parse(&mut Lexer::new(b"1 - 2 * (3 + 4 * 5 / 6) + -7 * -9 % 10")), Ok(-8)); |
结果显然是正确的。后面的内容其实就不影响使用了,可以跳过。
利用#[expand],得到过程宏输出的代码如下(为了美观,代码经过了格式化):
1 | // 两个宏用来集中管理safe和unsafe模式下的下标访问和不可达 |
DFA的图形是这样的:

再看一个巨大的LR(1) FSM(美观起见,我把Add等终结符换成了对应的符号,_Eof替换成了#):
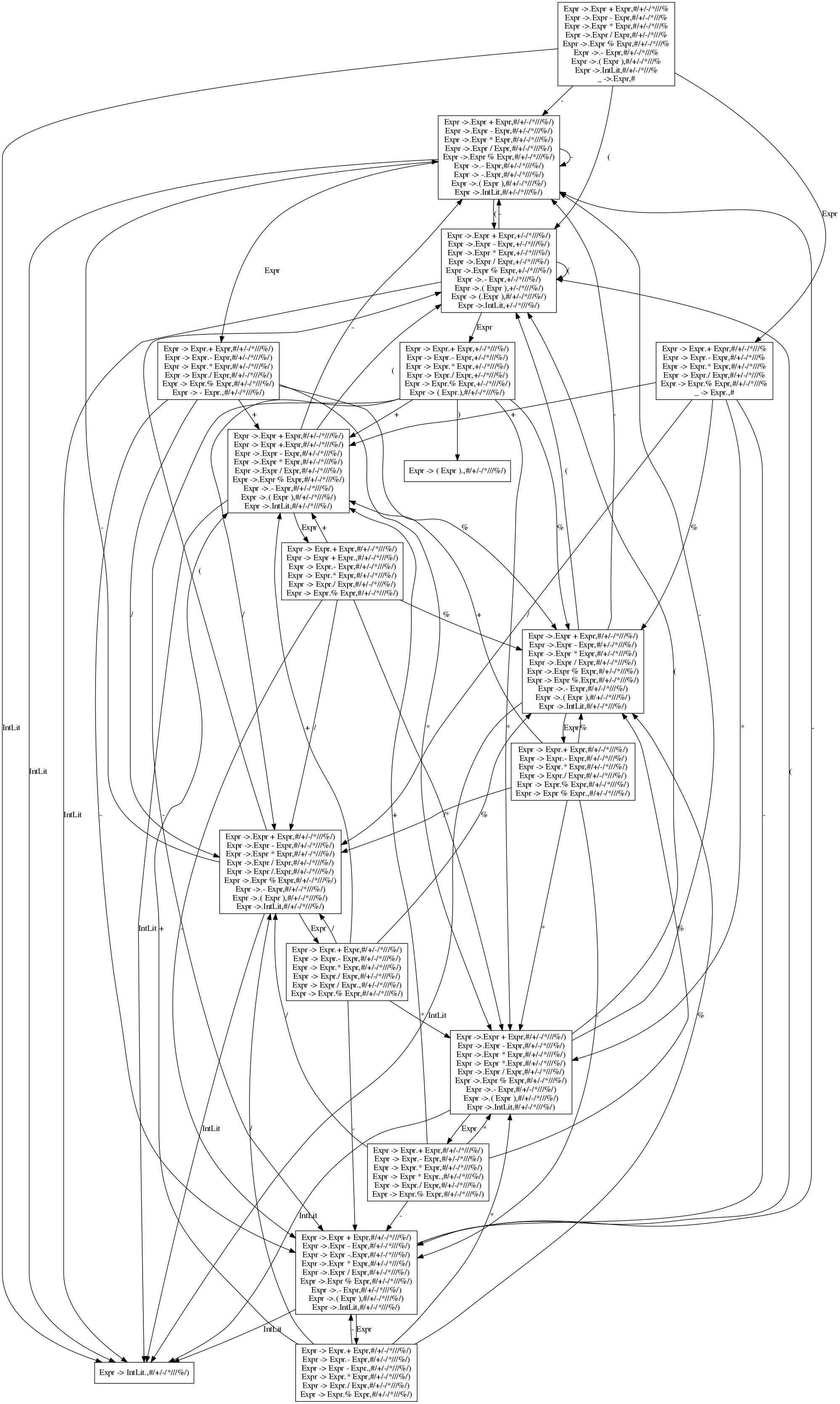
值得注意的是这个LR(1) FSM是没有经过解决冲突的处理的,例如图中的这一处:
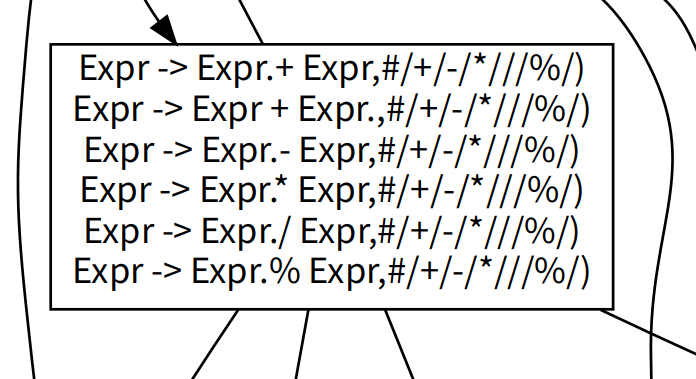
显然是有移进-规约冲突的。文本表示的verbose信息中体现了冲突的解决,这个片段对应于verbose.txt中的:
1 | State 13: |
可见这里所有冲突选择都被优先级和结合性的约束给消除了。
配置文件
如果你选择使用过程宏来生成代码,那么这一节可以完全跳过。
首先通过如下指令安装parser_gen,这个二进制程序就是负责读入TOML文件,输出指定的目标语言:
1 | cargo install --git https://github.com/MashPlant/lalr1 --features="clap toml" |
直接运行这个程序就可以得到帮助信息,因此这里不再介绍怎么使用它。
输入的TOML文件中可以包含如下字段(可以参照https://github.com/MashPlant/lalr1/tree/master/parser-gen/examples文件夹下三个目标语言的TOML文件一起阅读):
include:字符串,会被添加到输出的文件的开头位置priority:与过程宏中”编写lexer”一节的priority格式完全相同lexical:与过程宏中”编写lexer”一节的lexical格式完全相同parser_field:字符串列表,每个字符串表示parser结构体的一个字段start:字符串,表示初始非终结符production:列表,每个元素表示一组左端项相同的产生式,用一个TOML中的map表示,结构如下:lhs:字符串,左端项的名字ty:字符串,左端项的类型rhs:列表,表示一组产生式,每个产生式也用一个map表示,结构如下:rhs:字符串列表,每个字符串是产生式右端的一项rhs_arg:可选的列表,每个元素是一个长度为2的字符串列表,分别表示一个右端项在语法动作中的名字和类型。如果存在的话它会被用于类型检查,不存在的话这个检查就跳过了,生成的代码交给目标语言的编译器去检查。一般来说在TOML文件中描述这些类型信息太麻烦了,所以这个功能一般只用于过程宏模式下,这里直接不写这个字段就行了act:字符串,是目标语言的一段代码,表示语法动作。这里可以使用产生式的右端项,如果没有在rhs_arg中为它们起名字的话,Rust和C++中用_1,_2…等表示它们,Java中用$1,$2…等表示它们。Rust代码中这个语法动作最终应该是一个值(语句块的最后一个表达式如果没有分号的话就是整个语句块的值),C++代码中最终应该把结果赋值给__,Java代码中最终应该把结果赋值给$.$。这一段代码不是放在一个独立的函数里面的,而是都嵌在一个大函数里面,所以不要在这里写return之类可以改变控制流的语句prec:可选的字符串,如果存在,表示一个终结符,本条产生式的优先级与这个终结符相同,详细功能见”解决冲突”一节
parser_def:可选的字符串,如果不存在,就会定义一个名称为Parser的结构体,并为它定义parse函数;如果存在,就会直接为名称为它的结构体定义parse函数。目标语言为Java时这个字段会被忽略,总是会定义一个名为Parser的类。
生成的代码的基本功能和实现方式基本上都和基于过程宏的版本是一样的,所以没有必要重复介绍了。
解决冲突
我找了很多文档,也用yacc/bison做了很多实验,但仍然没有总结出一个完整的解决和汇报冲突的策略。既然这样,那我就不尝试实现它的规范了,lalr1以我的规范为准,如果和yacc/bison的表现不一致,那就不一致吧。(当然,如果它的表现和我声明的规范矛盾了,那肯定还是一个bug)
首先定义产生式的优先级(不定义产生式的结合性,因为没有意义且不会用到)。没有#[prec(Term)]时,产生式的优先级与右端最后一个终结符的优先级相同,如果右端没有终结符或者右端最后一个终结符没有定义优先级,那么这条产生式就没有优先级;有#[prec(Term)]时,产生式的优先级与与终结符Term相同,同样如果Term没有优先级,那么这条产生式就没有优先级。
先假设只有两种冲突选择:
- 若为规约-规约冲突
- 如果两个规约选择都有优先级,且优先级不相等,则选择优先级高的产生式规约
- 否则,选择先出现的产生式规约,且汇报一个冲突警告
- 若为移进-规约冲突
- 若待移进的终结符和待规约的产生式都有优先级(注意此时待移进的终结符一定也有结合性)
- 若待移进的终结符优先级高,则移进
- 若待规约的产生式优先级高,则规约
- 若二者优先级相等
- 若移进的终结符为左结合,则规约
- 若移进的终结符为右结合,则移进
- 若移进的终结符为不结合(有结合性,结合性是不结合),则既不移进也不规约,这两种选择都不合法
- 否则,移进,并且汇报一个冲突警告
- 若待移进的终结符和待规约的产生式都有优先级(注意此时待移进的终结符一定也有结合性)
以上就是解决冲突的全部内容了吗?这的确是文档里能找到的全部内容了,但我认为事情还没说完:在一个状态转移上,可行的选择可能大于两个。这一定是有大于两个规约选择,或者有一个移进选择和大于一个规约选择。
这之所以会成为一个问题,是因为没办法通过直接推广上面的两两比较来选择出一个”最好”的选择。在集合{ 移进,规约1,规约2,…,规约n }上如果定义x ≤ y ⇔ x和y冲突的时候选y,那么这个关系并不是一个合法的偏序关系,例子如下:
1 | 规约x:无优先级,出现在第2位 |
那么满足x ≤ y和y ≤ z,但是不满足x ≤ z。
即使先不考虑所有的需要”汇报一个冲突警告”的情形,也就是说产生式的优先级和终结符的优先级和结合性都存在且产生式的优先级不会相等,这时这个关系的确是一个偏序关系。然而如果需要处理结合性为不结合的终结符,仍然不能做出非常令人信服的选择(因为这个偏序集仍然不是全序的),例如:
1 | 规约x: 优先级1 |
有两种理解是合理的:一是规约y和移进z”抵消”了,所以选择规约x;二是规约x因为优先级不如规约y而不能选择,规约y和规约z因为终结符不结合也不能选择,所以没有选择。
我没有查到yacc/bison是怎么处理这些情况的,试图通过实验来归纳的时候也遇到了很多无法理解的问题,没有得出有用的结论。简单起见,规定如果有大于两个冲突选择,lalr1将拒绝生成代码。它会把冲突情况做出一定程度的汇报,然后失败退出。
字符集
上面一直在提”字符”的概念,这其实是一个非常模糊的表述,为了严谨起见有必要说明清楚。不过实际上我相信实际用lalr1编写的parser基本都是用来识别纯ASCII码的源程序的,所以应该是不会遇到字符编码相关的问题的。
re2dfa是完全基于字节的,也就是说从输入的正则表达式,到内部的处理过程,到最终生成的自动机,都假定了处理的字符集一定是在0, 1, ..., 255这个范围内的。最终生成的自动机对各种编码完全没有感知,只是逐字节读入数据并执行状态转移。所有的目标语言都是这样的:Rust中逐个u8地读入,C++中逐个char地读入,Java中逐个byte地读入。
不过这并不意味着生成的lexer只能识别单字节字符组成的字符串,因为即使输入的正则表达式中包含了需要多个匹配字节才能识别的字符,这对自动机来说无非就是多执行几次状态转移而已,并没有什么困难的(当然也有困难的情形,如前面所说[]内不支持多字节字符,就是因为如果要实现的话会增加不少复杂性,考虑[^a]和[a-b]的情况,其中a和b是多字节字符)。例如一个UTF-8编码的正则(测试)*的自动机如下:

这其中的230 181 139 232 175 149就对应于测试的每个字节。
在现在这样的实现下,可以很容易地精确描述出正则中的一些特殊字符的具体含义:
.:等价于[\x00-\xFF](大家可能不熟悉\xHH的写法,这是一个值为16进制数HH的字节)\s:等价于[\n\t\r ]\d:等价于[0-9]\w:等价于[0-9a-zA-Z_]
虽然这看起来没什么特别的,但是在对字符编码有感知的正则表达式实现中并不是这样的,例如Rust的正则库regex的规范中规定:
\w,\dand\sare Unicode aware. For example,\swill match all forms of whitespace categorized by Unicode.
举例来说,它的\s可以匹配中文全角空格,而re2dfa中的\s就不能。